Een Codeless Connector Platform (CCP) data-connector bouwen: deel 4
Home » Een Codeless Connector Platform (CCP) data-connector bouwen: deel 4
Gepubliceerd: 12-05-2025
In deze blogserie laat ik je zien hoe je je eigen Sentinel Codeless Connector Platform (CCP) data-connector kunt maken. Als dit je startpunt is, raad ik je aan eerst de vorige delen te lezen, want deze blog is best pittig als standalone.
Welkom bij de vierde en laatste blog in de serie, over het bouwen van een connector met behulp van Microsofts Sentinel Codeless Connector Platform (CCP). In het vorige deel legde ik uit hoe je je API-poller bouwt: het mechanisme dat ervoor zorgt dat Sentinel jouw API aanroept. In deze blog gaan we de laatste losse eindjes aan elkaar knopen: aan het eind heb je je eigen CCP-connector gedeployed en draaiend in je Sentinel-werkruimte.
Na deze blog zal je connector helemaal verbonden zijn. Laten we het fiksen!
Zoals altijd zijn alle bestanden die ik in deze blog gebruik terug te vinden op GitHub, dus voel je vrij om jouw bestanden te vergelijken met de mijne om het volgen wat makkelijker te maken. Laten we beginnen!
De laatste puntjes op de i
Als je tot nu toe hebt meegebouwd, ben je bijna klaar met je connector. Je hebt de API verkend, een GUI gebouwd die gebruikersinput accepteert en een mechanisme gemaakt dat Sentinel vertelt hoe de API van 1Password aangeroepen moet worden. Maar we moeten nog wat laatste dingen toevoegen. Om de connector te kunnen deployen, hebben we twee sjablonen nodig: eentje voor een Data Collection Rule (DCR) en eentje voor een Log Analytics Workspace (LAW)-tabel. Tot slot moeten we de vier sjablonen (UI, poller, DCR en tabel) samenvoegen in een groot deployment-bestand met behulp van het PowerShell-script createSolutionV3. We beginnen met de sjablonen!
Aan de slag met de sjablonen
Voor het deployen van onze connector hebben we nog twee bestanden nodig:
Een Data Collection Rule (DCR)-bestand. Een DCR definieert hoe de datastroom verloopt: waar begint het, waar eindigt het en wat gebeurt er onderweg. Je kunt een DCR gebruiken om data te transformeren (velden toevoegen, verwijderen of aanpassen), volledige rijen te filteren en te bepalen in welke tabel een record terechtkomt.
Een Log Analytics Workspace (LAW)-tabel. Een LAW-tabelbestand definieert de structuur van de tabel: welke kolommen er zijn en welk type gegevens ze bevatten (string, integer, datetime, enz.).
DCR’s kunnen vrij complex zijn, dus ik heb geprobeerd het sjabloon zo eenvoudig mogelijk te houden. Een DCR bestaat uit drie hoofdonderdelen:
streamDeclarations: definieert de inkomende datastroom(en) en het formaat van de binnenkomende data.
destinations: definieert waar de data naartoe kan. In ons geval is dat een Log Analytics Workspace.
dataFlows: ontvangt een of meerdere streams, past eventueel Kusto Query Language (KQL) toe voor filtering of transformatie, en stuurt het resultaat door naar de bestemming en de output-tabel.
We beginnen met destreamDeclarations. Er zijn meerdere manieren om deze te definiëren. Onderstaande codeblok toont het verwachte formaat: we definiëren een naam voor een stream (beginnend met Custom, aangezien we geen gebruik maken van een ingebouwde stream), gevolgd door het specificeren van de property-naam en het datatype voor elke kolom.
“streamDeclarations”:{
Om deze DCR zo eenvoudig mogelijk te houden, heb ik de drie datatypes die 1Password aanbiedt (aanmeldingsgebeurtenissen, auditlogboeken en itemgebruik) samengevoegd in één enkele inkomende stream. Dit is niet aan te raden voor productieomgevingen, omdat filteren extra kosten met zich mee kan brengen, maar het is een eenvoudige implementatie die gemakkelijk te reproduceren is. In onderstaand codefragment zie je onze gecombineerde inkomende stream.
“streamDeclarations”:{
Daarna moeten we de gecombineerde stream opsplitsen in drie tabellen op basis van unieke eigenschappen per datatype. Hiervoor gebruiken we KQL-transformaties binnen de dataFlows. De opzet van een dataFlows object zie je hieronder.
Het is een vrij eenvoudig object: we definiëren de stream die we als input willen gebruiken, transformeren deze tot op zekere hoogte met behulp van KQL, en sturen de resultaten vervolgens naar een bestemming en een specifieke outputStream (in ons geval een tabel). Aangezien onze inputstream echter een combinatie is van alle mogelijke logtypes van 1Password, zullen we wat KQL moeten gebruiken om deze van elkaar te scheiden. Gelukkig kunnen we de verschillende logtypen eenvoudig splitsen op basis van een unieke eigenschap:
De property object_type is uniek voor de Audit Events.
De property type is uniek voor de Sign-In Events.
De properties item_uuid en vault_uuid zijn uniek voor de Item Usage Events.
Wanneer we dit toepassen op onze skeleton-template, krijgen we het onderstaande sjabloon.
Een scherp oog zal wellicht een paar zaken opmerken die wat extra uitleg verdienen:
Alle dataFlows gebruiken de stream Custom-OnePasswordEvents als input. Let erop dat deze naam exact overeen moet komen met de eerder gedefinieerde streamnaam — anders weet de DCR niet waar de inputdata vandaan moet komen.
De property transformKql doet meer dan alleen data filteren: we hernoemen ook kolommen (met project-rename)! Dat doen we om een paar redenen: elke logregel die via een DCR wordt ingelezen, moet een TimeGenerated-property van het type datetime bevatten. Daarnaast zijn er enkele “gereserveerde” kolommen die we niet mogen gebruiken. De kolommen type en uuid vallen daaronder, dus hernoemen we die. Als we dat niet zouden doen, zou de DCR bij het deployen een foutmelding geven.
Je zult ook zien dat de verschillende dataflows allemaal verwijzen naar een destination, die we nog niet hebben gedefinieerd. Gelukkig is dat onderdeel heel eenvoudig: we definiëren het type bestemming — in dit geval logAnalytics — en geven vervolgens de resourceId en een naam op voor de bestemming.
Zoals je misschien is opgevallen, is deworkspaceResourceIdniet echt gedefinieerd: deze wordt ingevuld met een placeholder (aangegeven tussen accolades). Dat is logisch als je er even over nadenkt: stel je voor dat je connector uitgerold wordt naar duizenden workspaces wereldwijd — je zou nooit van tevoren de locatie of de resource ID van al die omgevingen kunnen weten. Gelukkig lost het Codeless Connector Platform (CCP) dit probleem voor ons op: wanneer we de connector definiëren, kunnen we placeholders gebruiken voor bepaalde eigenschappen. Zodra iemand onze (straks verpakte) connector uitrolt, worden die placeholders automatisch ingevuld met gegevens uit de deployment. Op die manier zijn zaken zoals resourceId en locatie altijd afgestemd op de doelworkspaces.
Als je al bekend bent met DCR’s, vraag je je wellicht af waar ons Data Collection Endpoint (DCE)-bestand gebleven is. Eén van de handige dingen aan het CCP is dat het veel werk op de achtergrond voor ons verricht. Een daarvan is het automatisch uitrollen van een DCE wanneer iemand onze connector deployt, en deze vervolgens koppelen aan de juiste DCR. We kunnen het DCE-bestand dus gerust weglaten, in de wetenschap dat het CCP dit automatisch afhandelt.
Nu we onze DCR hebben gedefinieerd, hebben we ook drie tabellen nodig. Het aanmaken van LAW-tabellen (Log Analytics Workspace) is vrij eenvoudig — zolang je maar zeker weet dat de property-namen en datatypes correct zijn. Je kunt zowel het tabelbestand als het volledige DCR-bestand terugvinden op GitHub. Voor de leesbaarheid heb ik hier enkele details en properties weggelaten, dus raadpleeg zeker de originele bestanden als je zelf meebouwt.
Het verpakkingsproces
Goed, we hebben nu vier verschillende templates: een UI-bestand, een poller-bestand, een DCR en een tabelbestand. Als je nieuwsgierig bent ingesteld, heb je misschien al geprobeerd deze te deployen — met als resultaat een reeks foutmeldingen. Dat komt omdat deze templates eerst gebundeld en verpakt moeten worden als een Sentinel Content Hub-oplossing, voordat ze succesvol uitgerold kunnen worden.
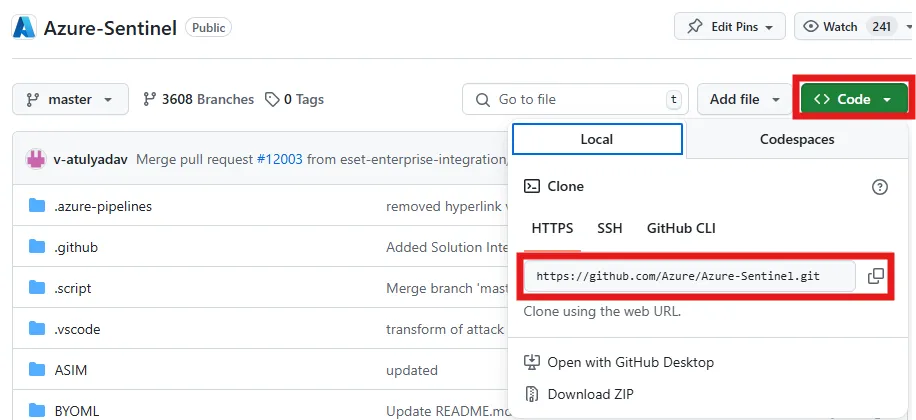
Om dat te doen, gebruiken we het PowerShell-script createSolutionV3, dat deel uitmaakt van de Sentinel GitHub-repository. Het verpakkingsproces kan licht variëren, afhankelijk van het besturingssysteem en de code-editor die je gebruikt, maar het verloop is in grote lijnen hetzelfde. Enige basiskennis van Git is handig, maar zeker niet vereist. De eerste stap is het clonen van de Sentinel-repository. Ga naar de Sentinel GitHub-pagina en klik op de knop “Code”. Kopieer de lokale HTTPS-URL; die gebruiken we om de repository lokaal te klonen.
De kloon link ophalen van GitHub.
Open een nieuw venster in Visual Studio Code en navigeer naar het tabblad Versiebeheer. Klik op de knop Clone Repository en plak de URL uit de vorige stap in het pop-upvenster. Je moet nu een pad opgeven waar de repository naartoe gekloond moet worden. Normaal gesproken maakt dat niet zoveel uit, maar aangezien veel scripts in de Sentinel GitHub gebruikmaken van semi-hardcoded paden, kun je het beste klonen naar C:\Github. Doe je dat niet, dan wacht je een wereld van ellende (en foutopsporing).
Klonen in Visual Studio Code.
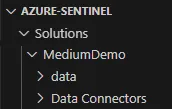
Het kloonproces kan even duren, aangezien de Sentinel GitHub-repository vrij groot is. Zodra het voltooid is, open je je nieuwe project en bekijk je de Verkenner (File Explorer) in Visual Studio Code. In de rootmap (de hoofdmap) van de repository zie je een reeks verschillende submappen. Elke map heeft een specifieke functie — bijvoorbeeld voor het opslaan van losse analytische regels, workbooks of playbooks. Om onze CCP-connector te kunnen maken, moeten we een oplossing (solution) aanmaken. Navigeer naar de map Solutions en maak daar een nieuwe submap aan. Voor dit artikel heb ik gekozen voor de naam “MediumDemo”, maar je kunt uiteraard een naam kiezen die voor jouw use case logisch is.
Binnen je nieuwe map maak je vervolgens twee submappen aan:
data: Deze map bevat een JSON-bestand dat je solution bij elkaar houdt. In dit bestand geef je o.a. aan wie de auteur is, welk logo gebruikt moet worden, welke content erin zit, welke metadata toegevoegd moet worden, enzovoort.
Data Connectors: Deze map bevat alle dataconnectoren voor je solution. In ons geval zullen hier uiteindelijk de bestanden terechtkomen die we hebben voorbereid voor onze CCP-connector.
Voordat we in het verpakkingsproces duiken, wil ik nog kort een aantal nuttige documentatiebronnen aanstippen die in de repository staan — maar die lastig te vinden zijn als je niet precies weet waar je moet zoeken. Deze blog behandelt alles wat relevant is voor de CCP-deployment, maar als je van plan bent om je eigen Sentinel-oplossing te bouwen, is het aan te raden om de volgende documenten te bekijken:
Guide to building Microsoft Sentinel Solutions
Guide to packaging Solutions using the packaging tool
Guide to packaging Solutions, CCP specifics
Setting up the connector files
Laten we beginnen met het opzetten van de connector
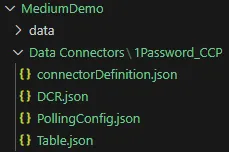
In je Data Connectors-submap maak je een nieuwe map aan. De naam mag je zelf kiezen, maar het is gangbare praktijk om de naam te laten eindigen op “CCP” wanneer je een CCP-connector bouwt. Voor dit artikel heb ik gekozen voor de naam “1Password CCP”. Nu je de map voor je connector hebt, kunnen we de bestanden toevoegen die we in de eerdere blogs hebben opgebouwd. Er is wel een conventie qua naamgeving die je moet volgen — anders herkent de packaging tool je bestanden mogelijk niet correct.
De naamgeving moet als volgt eindigen:
Het UI-bestand van de connector: connectorDefinition.json
Het poller-bestand: PollingConfig.json
De DCR: DCR.json
Het tabelbestand: Table.json
Je kunt er ook voor kiezen om géén prefix te gebruiken en exact deze bestandsnamen aan te houden — dat heb ik in dit voorbeeld gedaan. Het resultaat is een set-up zoals hieronder weergegeven.
Setup van de connector bestanden in de Data Connectors map.
Het voorbereiden van een metadata-bestand
De volgende stap is het aanmaken van het metadata-bestand. Dit bestand is vrij rechttoe rechtaan en vereist voor het verpakkingsproces van een CCP-connector. Als je als doel hebt om een oplossing te publiceren in de Sentinel Content Hub, dan gebeurt hier de magie: je kunt dit bestand koppelen aan een offerId en publisherId (beide afkomstig uit het Microsoft Partner Center Marketplace), waardoor het gebruik van jouw oplossing gelinkt kan worden aan je partnerprofiel. Daarnaast kun je ook beschrijvende tags toevoegen aan je oplossing en contactgegevens opgeven voor ondersteuning.
Voor ons voorbeeld volstaat het om het bestand te vullen met een aantal placeholders. Maar als je serieus aan de slag wilt met het bouwen van een production-ready oplossing, lees dan zeker de eerder genoemde documentatie grondig door. Daarin vind je uitgebreide informatie over dit bestand én instructies voor het opzetten van een aanbieding in de Azure Marketplace.
Het aanmaken van een solution-data-bestand
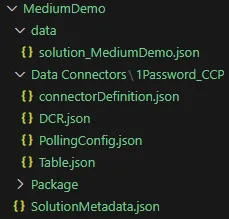
Dit is het laatste bestand dat we moeten aanmaken voordat we onze connector kunnen verpakken en uitrollen. Dit bestand hoort thuis in de map data en moet beginnen met de prefix solution_. Ik heb het mijne genoemd: solution_MediumDemo.json.
Ik zal niet alle eigenschappen van het bestand behandelen, maar licht de belangrijkste toe:
Name moet exact overeenkomen met de naam van de map die je hebt aangemaakt onder de map Solutions. Sommige tools gebruiken deze naam om naar bepaalde paden te navigeren — een andere naam dan die van je solution zal dus leiden tot fouten.
Logo verwijst naar een logo. Let op: alleen SVG-bestanden worden ondersteund. Als je van plan bent een volledige oplossing te bouwen, zorg er dan voor dat je het logo toevoegt aan de Logo-map in je pull request.
Data Connectors is het hart van de oplossing: hierin geef je aan waar je dataconnector zich bevindt. Let op dat dit een array is — een solution kan meerdere connectors bevatten! Voor een Codeless Connector verwijs je naar het connectorDefinition-bestand (het UI-bestand uit deel 2). De packaging tool gebruikt dat bestand als startpunt en vindt van daaruit het bijbehorende poller-bestand, dat op zijn beurt verwijst naar de DCR- en tabelbestanden.
Basepath is simpelweg het pad naar je solution-map.
Metadata moet overeenkomen met de naam van je metadata-bestand. Deze property is verplicht en mag niet ontbreken — je hebt dus hoe dan ook een metadata-bestand nodig, ook als je maar één CCP-connector wilt bouwen.
TemplateSpec moet altijd op true staan.
Na het invullen van al deze onderdelen zou je solution-map eruit moeten zien zoals op de afbeelding hieronder.
De connector bouwen en verpakken
We zijn bijna bij de finish! Het enige wat we nu nog hoeven te doen is onze connector verpakken met behulp van de packaging tool. Open een terminal in Visual Studio Code (of een andere omgeving naar keuze). Als je je nog steeds in de root van de repository bevindt, vind je de packaging tool op het volgende pad: .\Tools\create-Azure-Sentinel-Solution\V3\createSolutionV3.ps1
Wanneer je dit PowerShell-script aanroept, wordt je gevraagd om het pad naar het solution data-bestand. Geef hier het pad op naar je data-map (dus niet naar het solution-bestand zelf).
De packaging tool begint nu met het controleren van je bestanden. Dit is het moment waarop fouten het vaakst optreden — maar gelukkig worden die meestal vergezeld van een (minstens vage) beschrijving van wat er misgaat. Wanneer het fouten betreft rond CCP-connectors, is de oorzaak meestal te vinden in de onderlinge koppelingen tussen templates.
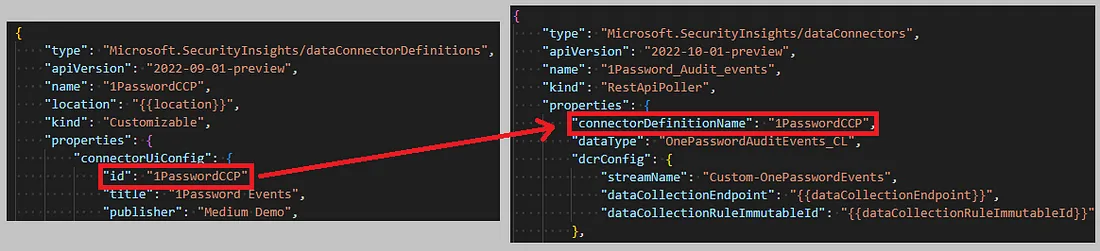
In je connectorDefinition-bestand bevindt zich een property id onder de sectie connectorUiConfig. De waarde van deze id moet exact overeenkomen met de property connectorDefinitionName in het PollingConfig-bestand. Dit is de koppeling tussen het UI-bestand en het poller-bestand.
De koppelingsproperty tussen UI-bestand en het poller-bestand.
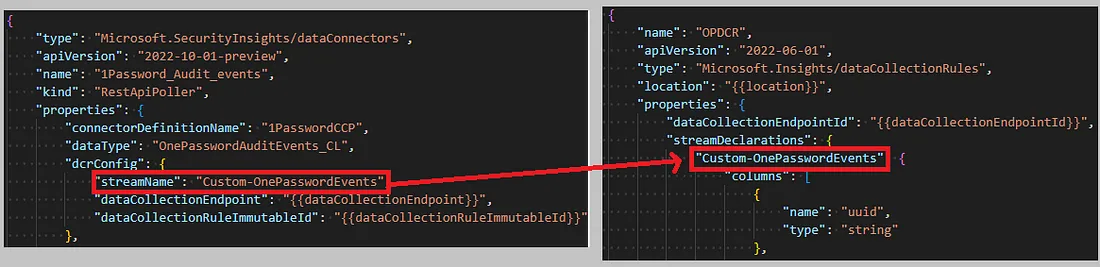
Evenzo bevat je PollingConfig-bestand een property genaamd streamName, die zich bevindt onder de sectie DcrConfig. De waarde van deze streamName moet exact overeenkomen met de naam van de stream die je hebt gedefinieerd onder streamDeclarations in je DCR-bestand — dit vormt de koppeling tussen beide componenten.
De koppelingsproperty tussen een poller en een DCR.
Tot slot is er de koppeling tussen je DCR en je tabelbestand. In je DCR bevindt zich onder dataFlows een property genaamd outputStream. De waarde hiervan moet exact overeenkomen met een tabelnaam zoals gedefinieerd in je tabelbestand — maar zonder deCustom-prefix.
De koppelingsproperty tussen een DCR en een tabel.
Als je solutionMetaData-bestanden, je solution-data-bestand en de onderlinge koppelingen tussen de templates correct zijn, zou de packaging tool zonder grote problemen moeten draaien. Het kan zijn dat er hier en daar een test faalt, maar doorgaans is dat niet de moeite waard om uitgebreid te gaan troubleshooten. De tool maakt een nieuwe map aan onder je solution-map, genaamd Package. Daarin worden meerdere bestanden gegenereerd, maar het enige bestand dat voor ons van belang is, is mainTemplate.json. Deze template kan uitgerold worden als een gewone ARM-template, waarmee we eindelijk onze connector kunnen deployen!
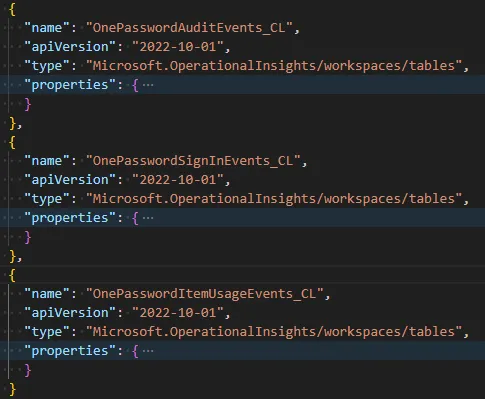
Kleine kanttekening: ik heb gemerkt dat de packaging tool soms niet goed omgaat met meerdere tabellen die in één bestand zijn gedefinieerd. Het is verstandig om dat even te controleren voordat je doorgaat naar de volgende stap. Rond regel 393 in het gegenereerde bestand zou de definitie van je tabellen moeten beginnen. Als dat er niet uitziet zoals verwacht (zoals op de afbeelding hieronder), dan is er iets misgegaan.
Zoals je kunt zien voegde de tool niet meerdere tabellen toe, maar één tabel met meerdere argumenten per property.
Gelukkig is de oplossing vrij eenvoudig: selecteer het volledige object dat de foutieve tabel definieert en verwijder het uit demainTemplate.json. Als je dezelfde templates gebruikt als ik, betreft dit doorgaans regel 393 tot en met regel 570. Ga vervolgens naar je oorspronkelijke tabelbestand en kopieer de volledige inhoud, met uitzondering van de array-haken (dus zonder de [ en ]). Plak dit dan op exact dezelfde plek in de mainTemplate.json waar je zojuist het foutieve object hebt verwijderd.
De sectie zou er uiteindelijk ongeveer zo uit moeten zien als op de onderstaande afbeelding (in het oorspronkelijke blog).
Je wilt dat je tabellen er zo uit komen te zien.
De grote finale: het deployen van onze connector!
Je hebt je templates zorgvuldig opgebouwd, alles verpakt, misschien een foutje opgelost, en nu is het moment eindelijk daar: je bent klaar om je connector te deployen en die heerlijke logs binnen te halen. Op dit punt heb je een reguliere ARM-template in handen, en kun je die uitrollen via eender welke methode je voorkeur heeft: PowerShell, Azure CLI, of de REST API. Maar om het eenvoudig te houden, gebruik ik in dit voorbeeld de Azure Portal UI.
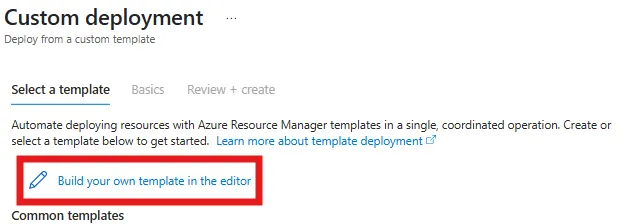
Navigeer naar de Azure Portal en zoek bovenaan in de zoekbalk op “deploy”. Selecteer vervolgens de optie “Deploy a custom template” (Een aangepaste template implementeren).
Selecteer de “Build your own template in the editor” optie.
In de editor kun je nu je volledige mainTemplate.json-bestand uploaden of plakken. Klik daarna op “Opslaan”, waarmee je terechtkomt bij het laatste deel van de deployment: het invoeren van de parameters. Wat je hier invult, bepaalt naar welke Log Analytics Workspace jouw connector uitgerold wordt. Het lijkt misschien vanzelfsprekend, maar controleer goed of Microsoft Sentinel geactiveerd is op de workspace die je kiest — anders zal de connector niet correct functioneren.
Geef de benodigde input.
Zodra je alles hebt ingevuld, klik je op “Beoordelen + maken” (Review + Create) en vervolgens op “Maken” (Create) om je template te deployen. De deployment zou binnen enkele seconden voltooid moeten zijn. Als alles goed is gegaan, kun je nu naar de opgegeven Sentinel-instantie navigeren, het tabblad Connectors openen — en jezelf aangenaam laten verrassen!
Is de connector nog niet zichtbaar? Klik dan even op de vernieuw-knop (Refresh), soms loopt de UI iets achter op de daadwerkelijke deployment.
Hoera, onze connector is daar!
De connector koppelen
Onze connector is succesvol gedeployed — maar we zijn er nog niet helemaal. Zoals je in de UI kunt zien, is de connector nog niet verbonden. Pas wanneer je in de UI de vereiste informatie invult en op de knop “Connect” klikt, wordt het laatste deel van de deployment uitgevoerd. Op dat moment worden de poller, de DCR en de tabel daadwerkelijk uitgerold. Dat betekent ook dat eventuele fouten in die templates pas zichtbaar worden tijdens het verbinden van de connector, niet tijdens het eerdere packaging- of deployproces. Let hier goed op bij het bouwen en testen van je eigen connector: test altijd een volledige deployment inclusief connectie, anders is de kans groot dat je kritieke fouten in je templates over het hoofd ziet!
Geef de juiste informatie in en klik op ‘connect’
Voorzie de UI van de vereiste informatie en klik op “Connect”. Je zult zien dat er daadwerkelijk een deploymentproces opgestart wordt — dit kun je volgen via het notificatievenster rechtsboven in de Azure Portal. Na ongeveer een halve minuut zou je de melding “Deployment succeeded” moeten zien. Dit betekent dat:
de onderliggende templates zonder fouten zijn uitgerold,
de poller succesvol de API heeft aangeroepen,
en dat er een geldige statuscode is teruggegeven op het verzoek.
We zijn verbonden!
Het zou nu niet lang meer moeten duren voordat de eerste logs beginnen binnen te komen. Zorg ervoor dat er daadwerkelijk gebeurtenissen zijn om op te vangen — log een paar keer in en uit bij 1Password — en binnen ongeveer 30 minuten zouden de eerste logs zichtbaar moeten zijn in je Log Analytics Workspace.
Logs!
Gefeliciteerd! Door deze blogreeks te volgen, ben je nu in staat om een API te verkennen, de gevonden eigenschappen te gebruiken om een Codeless Connector-template vanaf nul op te bouwen, en de volledige connector te packagen en uit te rollen binnen Microsoft Sentinel.
Tot slot
Al met al vind ik de Codeless Connector een fantastische toevoeging aan de toolkit van Sentinel. Ik zou niet zeggen dat het instappen eenvoudig is, maar de voordelen wegen wat mij betreft ruimschoots op tegen de complexiteit van het ontwikkelproces. Ik hoop dat deze blogreeks je goed heeft geholpen om het merendeel van dat proces te begrijpen, en ik ben benieuwd naar de connectors die jullie gaan bouwen!
En tot slot: enorme dank als je het tot hier hebt volgehouden! Ik waardeer alle positieve feedback die ik heb ontvangen op de eerdere blogs enorm, en ik hoop dat ook deze reeks de moeite waard voor je was.